

データアナリストとしての成長を求めて出版社からIT企業に飛び込んだ話

はじめまして!株式会社ベーシックでデータアナリストをしています、AKBと申します。2023年の4月に中途で入社しました。現在はノーコードでフォームが作成できるSaaSプロダクトである「formrun(フォームラン)」に関する分析業務に取り組んでいます。
ベーシックでは、新入社員が「入社エントリ」という形でnoteを執筆することがもはや文化となっているのですが、この文化がベーシックに入社することを決めた理由の1つにもなりました。そのnoteを、今度は私が執筆できることはとても嬉しくもあり、同時に責任も感じています。
今回は、私自身の転職の経緯や転職に期待していたこと、実際入社してみてどうだったかをお話していきたいと思います。下記に当てはまる方は読んでいただければ嬉しいです。
・ベーシックのデータサイエンス・データエンジニアリングなどのデータ関連業務に興味がある方
・ベーシックのカジュアル面談に応募しようか迷っている方
転職を考えたきっかけ
まずは、軽く自己紹介をさせていただきます。自分で申し上げるのもなんですが、ちょっと変な経歴を持っています。ざっくりまとめると以下のような形です。

薬剤師の免許までとって書籍編集者になっていたり、2020年に突然、書籍編集者からデータアナリストになっていたりと、転職活動中にも経歴についてはかなりツッコミをいただきました。(詳しくは、カジュアル面談や懇親会でお話ししましょう笑)
ここで注目していただきたいのは、そこではなく、2016年から2023年までの7年間同じ会社に居続けているというところです。
7年間も同じ会社にいると仕事にも慣れてきますし、昇進して収入の面でも安定してくるものかと思います。実際に私自身も、2020年にデータアナリストに転向したとはいえ、どの時期にどんな仕事があるのかを大体は把握できるようになっていました。そんな折、2つの気づきがありました。
1つ目は、自分がこのまま働き続けると、おおよそ同じことを65 - 32 = 33周(定年年齢 - 現年齢)も続けなければならないことです。
もちろん周りの環境が目まぐるしく変わっていくため、それに応じて仕事も変わってくることはありえます。とはいえ、同じ会社にいる限りは自分の仕事はそう大きく変わることはなく、自分の成長も鈍化してしまうのではないか、と思いました。
2つ目は、会社を変え、そこに適応していくために必要な気力・体力はどんどん落ちていくのではないかということです。
私より年齢が上の方は皆、口を揃えて「35歳を過ぎると今までと同じように仕事ができなくなる」と言っています。もしそれが本当だとすれば、会社を変えて働くことは年齢を重ねるにつれて難しくなるのではないか、と思いました。
以上の2つの気づきをきっかけに、転職活動に踏み切ることにしました。
転職の軸
転職の一番の軸は、データエンジニアリング、機械学習モデル開発の両方に関われる環境かどうかでした。データ関連の業務についてざっくり整理すると以下のようになります。

(1) データエンジニアリング:データを溜める分析基盤の開発・調整を行う業務
(2) データ分析:分析基盤からデータを取り出し、新しい知見を見つける業務
(3) 機械学習モデル開発:(2)データ分析から得られた知見を用いて、予測等を行う機械学習モデルを開発する業務
前職では主に(2)データ分析の業務を行っていましたが、(1) データエンジニアリングと(3) 機械学習モデル開発に関わることはほとんどありませんでした。
しかし、データ関連業務を依頼する方から見れば(1)(2)(3)の区別をすることは難しく、(1)や(3)に関わる依頼が私にくる場面もしばしばありました。その度に専門の方に引き継いでいたのですが、依頼を引き継ぐために使う時間が非常に勿体無いと感じていました。
自分で(1)~(3)までできてしまえば引き継ぎに要する時間が0になりますし、データ関連業務を全て自分でこなせることは今後のキャリアを考えてもプラスになるはずです。そのような考えから、次の転職先では(2)データ分析だけでなく、(1)データエンジニアリングや(3)機械学習モデル開発の業務経験が積めそうな会社にしようと決めました。
転職活動開始〜ベーシックの入社まで
ベーシックに対して抱いた印象
転職活動を進める中で、ベーシックでのアナリストの募集を見つけました。しかし恥ずかしながら、当時はベーシックという会社を全く知らない状態だったため、企業理解を深めるためにベーシックのnoteを確認しました。160本近くすでに公開されている記事に一通り目を通し、以下のような印象を抱きました。
(A) データ分析チームが立ち上がったばかりであり、先述の(1)データエンジニアリングや、(3)機械学習モデルの開発の経験も積めそう。
(B) 仕事に対して社員一人一人が熱い想いがあり、他者へのリスペクトも備えている。
(C) 人事評価制度が充実している。
(A) については、データチームのマネージャーである深川が執筆したnoteを読んでの印象でした。こちらの記事を読んで、ベーシックのデータチームではデータ基盤を整備中であること、そして解約件数や新規獲得件数等の予測に取り組んでいることが分かりました。
これはまさに私の転職の軸であった(1)データエンジニアリングや、(3)機械学習モデルの開発に該当し、今後それらを強化していく仕事にとても興味をそそられました。
(B) については、一人一人のnoteを読んでいただくとよくわかると思います。
160本あるどのnoteを読んでも、仕事に対しての熱い想い、他者へのリスペクトが伝わってきました。
特に感動したのは、新卒1年目でカスタマーサポートの山下が、よりよいサポートの提供のために「定量化→仕組み化→アウトプット改善」のプロセスを回し続けていたことです。サポート1つとっても「ここまでこだわるのか!」と思い、それであれば組織全体としても目的達成のために徹底的に動いているのだと思いました。
また各々のnoteの記事には他の社員の記事へのリンクも多かったです。会社全体として「チームでこの目標を達成したい」という想いが強く、他のメンバーやその仕事に対するリスペクトがあるからこそ、各社員がnoteを読んでいるのだと感じました。そのような熱い想いをもつ社員が多いということは、組織としても非常に強いことが想像できました。これらのnoteのおかけで、私のベーシックに対する期待値は面接前から高かったです。
(C) は、以下の記事でも紹介されているのですが、入社年次や年齢、性別、国籍に関係なく、各人の業務成果への期待で評価する制度です。
まずはメンバー各人の強みや期待する役割を議論し、その上で次の半期で期待する役割を「難易度」「組織影響度」「裁量度」「対人関係スキル」の4つの指標で点数化します。そしてその合計点に応じてグレードを決め、そのグレードに応じたミッションと達成基準を当該社員とすり合わせていく制度です。
私の周囲の方々の話を聞いていても、これだけ細かく評価制度を体系化している会社はなかなかありません。ここまでしっかり決まっていれば、一部の人間のブラックボックス化された評価によって仕事に対するモチベーションが上下することもなさそうだと感じ、ベーシックに応募する最後の一押しとなりました。
心が動いた出来事
数回の面接の時には、上記の(A)〜(C)の印象が間違っていないかを確認するようにしていました。また、社員同士の雰囲気やコミュニケーションの温度感、カルチャーが自分に合うかを事前に直接肌で感じたいと思い、オフラインの面接をお願いしたり(本来はオンラインで完結します)、会社で開催されるオフライン懇親会にも入社前の段階から参加させていただきました。
その中では、何より社員の人柄の良さを強く感じました。面接でも懇親会でもとても話しやすい方が多く、仕事に関しての想いを各々語っていたことから、社員同士気兼ねなく意見が言い合える環境であることを感じました。
また、私の面接を担当していたメンバーと面接後に話す機会もあったのですが、「面接の時はベーシックの魅力をうまく伝えられなかったから反省していた」という言葉を伺い、志願者に会社のことをきちんと知ってもらうために雰囲気作りや話の内容に気を配ってくれていたんだ、と温かい気持ちにもなりました。
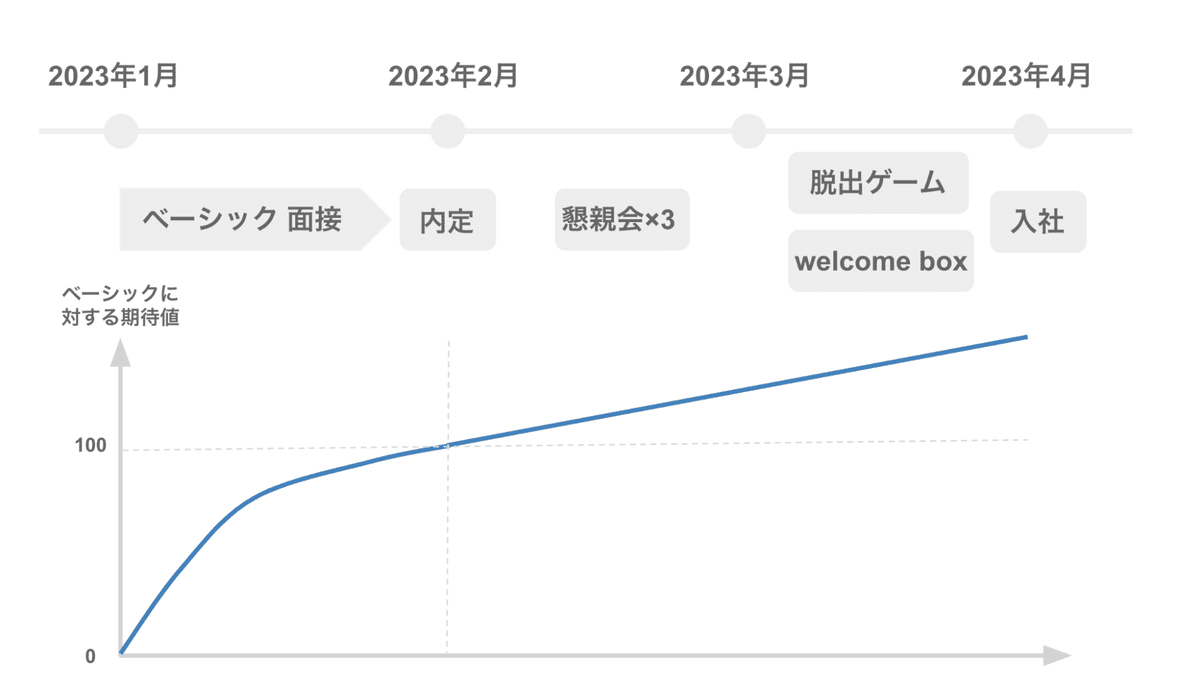
そしてもちろん、自分が転職の軸としていた「データエンジニアリング、機械学習モデル開発の両方に関われる環境かどうか」の条件を満たしていたため、ベーシックに対する期待値が100の状態で、2023年の2月に内定を承諾しました。
そこから入社までの2ヶ月間は、前職の引き継ぎや有休消化を行いつつ、入社前にもかかわらずベーシックの懇親会に3度誘っていただいたり、社員有志の「謎解きコミュニティ」に参加して脱出ゲームをしにいったりすることで、「人柄の良さ」の部分はより確信に変わっていきました。
また、3月の中旬にはベーシックのWelcome Boxが届き、より一層入社日が楽しみになってきました(Welcome Boxについては弊社の長田がnoteにまとめています。)

結果的に内定時に期待値が100となった後もベーシックへの期待値は100を超えて伸び続けました。
現在挑戦していること
そして、4月より晴れてベーシックに入社し、現在はPLG事業部のデータアナリストとして勤務しています。
※ PLG…Product-Led-Growthのこと。一言でいうと、「プロダクトによってプロダクトを売る」ビジネスモデルなのですが、その詳細は弊社PdMのfumiがまとめていますのでこちらをご覧ください。
このPLGというビジネスモデルは、営業組織がいないからこそ、データに基づいて意思決定を行い、データに基づいてPDCAを回していく必要があります。そのため、PLG事業部全体として、データへの関心がとても強くなっています。
それゆえ、様々なグループから分析案件が発生し、単なる集計に止まらない分析手法も試すことが可能です。また、分析・レポーティングだけでなく、データパイプラインの構築から予測モデルの作成までデータに関してほぼすべての部分を担当できる形になっています。実際に、私は現在以下の3つの業務に取り組んでいます。
1. 売上数値のモニタリングプロジェクト
2. お問合せ数削減プロジェクト
3. 有料件数予測モデル作成プロジェクト
「1. 売上数値のモニタリングプロジェクト」は外部サービスで管理していた売上データを分析基盤に移行することによって、より柔軟な分析・可視化を実現するプロジェクトです。将来的にはこれらの数値を学習データとして、売上の予測モデルを作成する予定です。
プロジェクト開始時には売上データが分析基盤上にありませんでした。
そのため、売上データを管理するサービスから自社の分析基盤にデータを移行するパイプラインの構築からスタートする必要がありました。入社して間もないタイミングでしたが、パイプライン設計から実装時のツール選定まで全て自分に任せてもらえました。
そして、これらの売上データを元にして、LTV(Life Time Value)が大きい(小さい)ユーザーのセグメント探索や売上件数・金額の予測などを行います。そしてこれらの解析を行う手法も自ら考案する必要があります。

「2. お問合せ数削減プロジェクト」はformrunのカスタマーサポートに届くお問合せの特性を解析することによって、お問合せの数を減らすことを目標にしたプロジェクトです。
現在はお問合せに至るまでのユーザーの行動をモデル化することで、「FAQやchatbotの内容に問題があるのか」「導線に問題があるのか」を切り分けつつ、どこを改善したらユーザーがよりスムーズに疑問を解決できるのかを探っています。

カスタマーサポートの方が作成したこのモデルに合わせて、それぞれに何人のユーザーがいるのかをモニタリングし、施策を考えています。
「3. 有料化件数予測モデル作成プロジェクト」は、formrunの有料化件数の予測モデルを作成するもので、いつ・どのセグメントに新規有料化ユーザー獲得のための費用を投入すべきなのかの判断をサポートするプロジェクトです。予測する数値がトレンドや季節性を持っているだけでなく、施策の実施でも数値が大きく変わっているのでそれらをどう切り分けて管理していくかがポイントになっています。
ベーシックではこれまで、データ分析基盤の整備や統計的な分析から新しい知見を見つける業務が多かったのですが、このような予測モデルの作成など、機械学習を用いて課題を解決していく案件も徐々に増えてきています。
別プロジェクトとしてユーザーの解約予測モデルを構築するプロジェクトも進行中であり、データグループ内で試行錯誤しながら機械学習のプロジェクトを進めるためのフレームワークも整備している段階です。私自身も機械学習のプロジェクトは初めて経験するので常に勉強をしながら進めており、自分の技術レベルが日々上がっていくことをすでに感じています。

転職の軸のところでもお話した通り、私はデータエンジニアリング、機械学習モデル開発の経験が積める環境を求めて転職をしました。しかし、これらの分野についてはあまり経験がなく、業務時間内も業務時間外もひたすら勉強の日々となり、お世辞にも楽な日々とは言えません(笑)
しかし、ベーシックは入社して間もない段階から、様々な挑戦機会をいただけるのと同時にサポート体制も充実しています。例えば、データエンジニアリングや機械学習モデル開発でいうと、データ活用の専門企業である株式会社R SQUAREDさんをはじめとした外部パートナーさんに相談を行う場も設けられています。
このように周囲のサポートも手厚いので、データエンジニアリング部分に携わりたいと考えているデータサイエンティストの方にも良い環境だと感じています。
最後に
入社してからあっという間に3ヶ月が経ちました。入社前に期待していたことに関して入社後の自分の評価は率直に以下のような形です。

(1)の「データエンジニアリング・機械学習モデルの開発経験」に関しては、現在は担当事業部から挙がってくる短期の分析案件をこなしながらデータのキャッチアップを行ったり、まだ分析基盤に移せていないデータを分析基盤に移行し、ダッシュボード化することで、今後の分析に生かせるように挑戦しているところです。

ただし、まだ理想とする業務経験をこれから積んでいく段階なので、これから自分が行動することによって「期待通り」な状態に近づけたいと思っています。
(2)の「社員の仕事への想い・他者へのリスペクト」については入社前に抱いた印象の通りでした。一人一人が自分の仕事に対して熱意をもって仕事に取り組んでおり、かつ他者へのリスペクトも持ち合わせています。
ベーシックでは基本的にSlack上でやりとりをしているのですが、どのメンバーもいつも丁寧に返信してくれるので、入社初日にして96件の返信があるスレッドが出現しました(笑)

(3)の「人事評価制度」についてはまだ評価のタイミングではないため、「期待通り」とは評価できる段階ではありません。しかし、個人のミッションシートで上半期に自分がやるべきことが明確に定義されており、分析力スキルの向上もミッションの一つとして定められているので、自身のスキルアップがそのまま評価に繋がる仕組みにもなっています。なので、非常にやりやすい状態であることは間違いありません!

ここまで読んでいただき、ありがとうございました。
ベーシックを知ってから入社するまでのプロセスと入社した後に感じたギャップについてイメージできるようにnoteを書きました。挑戦を後押ししてくれる環境であり、裁量が大きい状態で仕事ができるので、難易度が非常に高い課題をデータエンジニアリング・データサイエンスを用いて解決していきたいと考えている方にとっては非常に魅力的な環境であると思います。
弊社データチームマネージャーの深川がベーシックのデータチームの取り組みについてより詳細にまとめていますので、よろしければご覧ください。
このnoteをご覧になってベーシックに興味を持って下さった方は、ぜひ採用サイトも覗いてみてください。将来皆様と一緒に働けることを楽しみにしています!